Contents
How the Data Appeared Online
In March 2024, internal documents from the Google API Content Warehouse were accidentally published on GitHub. These documents contained descriptions of the algorithms and ranking factors used in Google’s search engine.
Later, these documents were discovered by Erfan Azimi, the head of EA Digital Eagle, who brought them to the attention of Rand Fishkin, a well-known figure in the SEO community. Fishkin then publicized the leak.
Did Google Lie to Us?
In short, yes. The Google leak revealed that many of the company’s public statements do not match reality. The documents disclose numerous ranking factors that the company had kept hidden, including some that they explicitly denied using. Let’s see what John Mueller, one of the main search specialists at Google, had to say about the algorithms earlier.
Domain Authority
Google has claimed that it does not use Domain Authority (DA) to rank websites. However, the leaked documents mention a “siteAuthority” attribute in the CompressedQualitySignals module, which is used to assess sites’ DA. This confirms the existence of an internal algorithm that considers a site’s overall authority.
Behavioral Factors in Google
It turns out that Google does monitor clicks. Although CTR (Click-Through Rate) and dwell time are not explicitly mentioned in the documents, other indicators exist.
The NavBoost system monitors various types of clicks, including bad clicks, good clicks, longest clicks, unsquashed clicks, and last longest clicks. This system treats user clicks as votes: it records the number of unsuccessful clicks and segments the data by countries and devices. The primary indicator of success is long clicks.
Sandbox
John Mueller explained that new websites need more time to rank because of the natural accumulation of factors such as content, backlinks, and engagement rather than a deliberate delay from Google. However, the reality is more complex.
The leaked documents revealed that Google has a mechanism that affects the visibility of new websites until they build up sufficient trust and authority. In the documentation for the PerDocData module, there is an attribute called “hostAge,” which is used “to sandbox fresh spam in serving time.”
Impact of Algorithms
Algorithms play a crucial role in keeping search results relevant and high-quality. Two of the most well-known ones, Penguin and Panda, are designed to fight against low-quality content and manipulative links. But their impact has turned out to be more significant than anyone expected.
Penguin
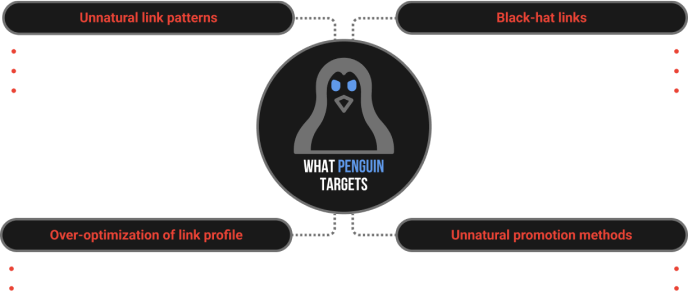
The leak reveals that Penguin targets low-quality, spammy, and irrelevant backlinks. Only good links positively impact rankings, while bad ones lower them. Penguin closely examines texts for unnatural anchor patterns or over-optimization and penalizes sites using black hat link-building methods like doorway pages and link manipulation. Its goal is to quickly restore rankings for sites that improve their link profiles after penalties and to punish spammers.
We already knew most of this, but thanks to Google for confirming it. What’s really interesting in the leak is the frequent mention of the term “local” in many modules, such as “droppedLocalAnchorCount.” It turns out Google analyzes internal linking and ignores links suspected of over-optimization.
Panda

There has long been a filter tracking content quality—Google Panda. The details of how the filter works were not disclosed, and Google denied considering user behavior factors on pages.
From the leak, we learned that the Panda algorithm targets low-quality or minimally useful content and demotes sites with such materials in the rankings. Rankings are heavily influenced by user behavior metrics, such as the time spent on the page and how users interact with the content. A high bounce rate negatively impacts ranking.
The quality of the external link isn’t the only thing that matters—relevance is also critical. Low-quality links clearly lead to demotion, but it’s also important to ensure that the anchor text matches the link: irrelevant text and links negatively affect ranking.
What Else Did We Learn from the Leaked Documentation?
Publication Dates
The system considers publication dates when determining page relevance. It looks at the content’s publication date (bylineDate, syntacticDate). Google considers both the page’s publication date and the URL’s creation date to assess relevance more accurately. This is managed by the attribute TYPE_FRESHDOCS.
Trust of the Homepage
Yes, the trust of the homepage is more important than we thought. The leak confirms that the authority of a website’s homepage (siteFocusScore) impacts the ranking of all pages on the site in Google, and the overall domain authority affects its visibility in search results.
Backlinks
The more authoritative the referring site, the better your site will rank. Additionally, the closer a site is in terms of the number of links to one of these trusted sites, the more valuable these links are. In the documentation, this is referred to as the PageRank-NearestSeeds (PagerankNs) attribute, which has replaced the classic PageRank. This means that links obtained from authoritative sites have a high value.
Original Sources of Information
You can view the original information published on GitHub via this link. For a more detailed explanation of what this means for SEO specialists, you can read Rand Fishkin’s analysis on SparkToro.
What Should an SEO Specialist Do?
Given the new data about Google’s algorithms, it may be time for SEO specialists to reassess some strategies. Obviously, the search engine places significant emphasis on content quality and authority. Link-building strategies also need optimization: pay closer attention to the relevance and quality of sources. Yes to good links, no to bad ones.
Additionally, change your approach to working with behavioral factors. Sure, easy navigation, fast page loading, and responsive design are old and well-known aspects. But user experience and behavioral factors are more critical for Google rankings than we thought.
DO’S
- Use as many relevant entities as possible (considering NLP)
- Add unique value to your content
- Consider the last 20 changes for the URL
- Fresh content (links from the media are prior considered high quality)
- Boost overall site trust
DON’T’S
- Unoptimized meta tags (especially title)
- Black hat SEO
- Poor usability
- Low-quality content
- Blind trust in official statements when they talk about ranking algorithms 🙂
Conclusions
1. The leak of Google’s algorithms has confirmed many suspicions and theories. Of course, we are pleased about the leak, but not with all of our hearts. Now that theories have become reality, many strategies must be restructured, and we will have to learn to work under new conditions.
2. The most important aspects for Google are:
- Quality > Quantity: It’s better to acquire fewer high-quality links than many medium or low-quality ones (remember Penguin).
- Content quality is a top priority.
- The overall authority of the site is crucial.
3. You shouldn’t trust big corporations. Surprising, isn’t it?


