
Contents
Search optimisation in 2025 is going through a fundamental shift. The focus is moving from matching text to keywords to working with entities, the objects and concepts behind search queries.
This guide explains entity-based SEO in detail. Viktor Pryadilshchikov, SEO Team Lead at Why SEO Serious, walks through how the shift began, how entity search works, and why moving beyond a “keyword-first” mindset has become essential. You’ll also learn how entities are formed, why structured data matters, and how to use it without introducing errors.
From keywords to entities: a new SEO paradigm
Not so long ago, SEO revolved around keywords, the phrases people typed into search engines. Specialists selected these phrases and added them to the text in the right density and in the right places.
But this approach had a limitation: search engines often couldn’t understand the meaning behind a word. Apple could refer to the brand or the fruit. Search engines had to guess user intent based on a narrow set of characters.
With the rise of natural language processing (NLP) and machine learning in the 2010s, semantic search became possible. Algorithms like Hummingbird, RankBrain and BERT allowed Google to move beyond literal word matching.
Modern search treats Apple as an entity — a unique object with specific attributes and connections. It might be a company or a fruit, but crucially, it can be identified unambiguously.

In essence, SEO has evolved from counting keyword density to evaluating relevance and depth. This shift is one of the most important in the industry. When you optimise for meaning instead of a string of characters, you speak the same language as the search engine.
What entities are and why they matter
In SEO, an entity is any identifiable object or concept. It can be a person, a place, an organisation, a product, an event or an idea — anything that can be clearly defined.
The distinction matters: a keyword is only a string of text, whereas an entity is an information unit with a set of connected attributes.
For example, the term New York can have several meanings. But in Google’s knowledge base, New York City and New York State are stored as different entities, each with a unique identifier and its own set of relationships. This is why a user searching for “best pizza places New York” is interpreted as referring to New York City, not the state or anything else.
Entities carry context. Each entity comes with a web of related concepts. The entity Steve Jobs is linked to Apple, Pixar and the iPhone. When someone searches for him, Google brings in not only facts about Jobs but also connected entities such as films, quotes and companies.

Why entities matter for SEO
One of the main advantages of entities is precise intent recognition. Search systems detect the meaning behind the words and deliver content that fits this meaning. A user may write one thing but mean something different, and the algorithm is able to interpret that.
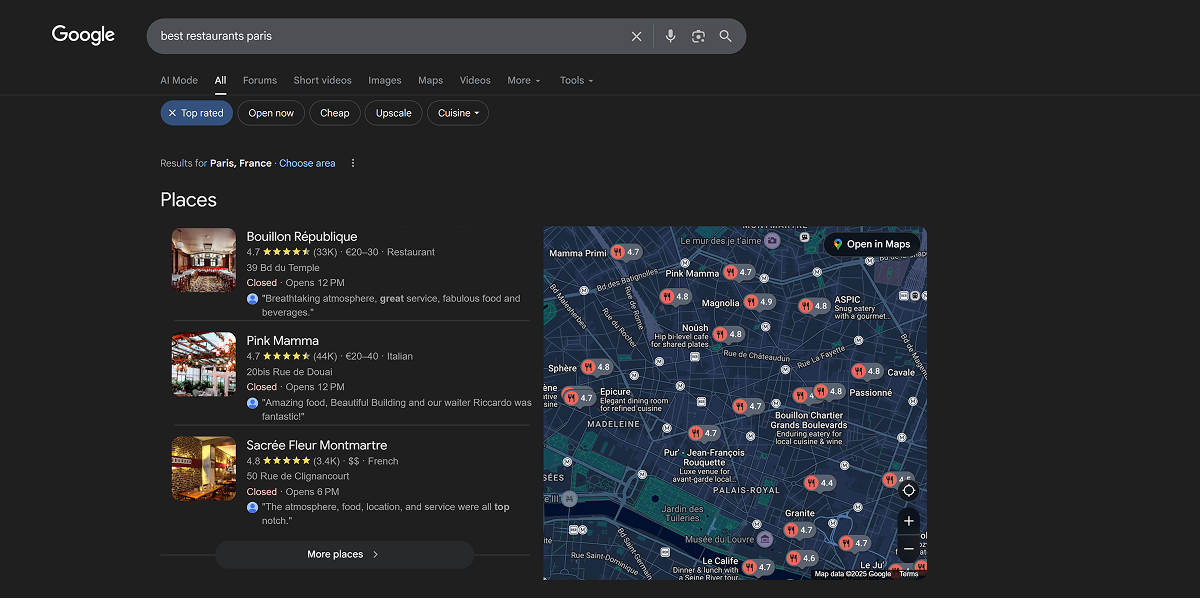
For example, someone might search for “best restaurants Paris”. There may be no explicit entities in the text, but the search engine understands the underlying concepts: the place (Paris), the category (restaurant) and the idea of a ranking or a list of top options. Based on this, the results show curated selections, maps and reviews. If the algorithm relied only on matching the words “best” + “restaurants” + “Paris”, the results would be far less accurate.
Entity-based optimisation also increases the relevance of content. Pages built around entities usually provide deeper coverage of a topic.
A richer network of related entities increases the chances that a page will satisfy different search queries, even without exact keyword matches. This is especially noticeable in voice search. Voice queries tend to sound natural, for example: “where can I get sushi nearby” or “which river is longer, the Rhine or the Danube”. Content structured around entities responds better to these conversational requests. As a result, the page answers the user’s intent with fewer steps. This improves satisfaction and strengthens behavioural signals.
Give your content a clearer place in search
Entity-level clarity helps Google match your work to the right intent.
We support this by structuring your content around well-defined entities and relationships, making your site more predictable for search engines.
How search engines recognise entities and use them in ranking
How do search engines identify entities in text and then use this information in their algorithms? The process has two stages: recognising the entities mentioned in the content, and applying knowledge about these entities during ranking.
How search engines recognise and store entities
Google and other search systems build their knowledge base in two ways:
- From authoritative sources. Algorithms rely on established databases. Wikipedia became the foundation of the first Google Knowledge Graph. They also use Wikidata, IMDb, Britannica and other structured reference sources. These provide verified entities and their attributes.
- From web documents. New entities appear faster than databases can update. Search engines, therefore, extract them from unstructured content.
To detect a new entity, algorithms analyse context. If a person’s name consistently appears next to an organisation that is already recognised as an entity, the system may conclude that this is a new notable entity. For example, if many publications mention “Jeff Bezos, founder of Amazon”, the algorithm can infer that Jeff Bezos is a distinct entity worth adding to the knowledge base.
There is also an assessment of significance. It is easier to become an entity in a narrow niche than in a broad one. A local expert may qualify as an entity within their field or region even if they are not widely known in the industry.
Once identified, an entity receives a place in the knowledge graph and a unique Entity ID.
According to patent data, the Google Knowledge Graph contains billions of entities, with around five billion objects and more than 500 billion facts about them.
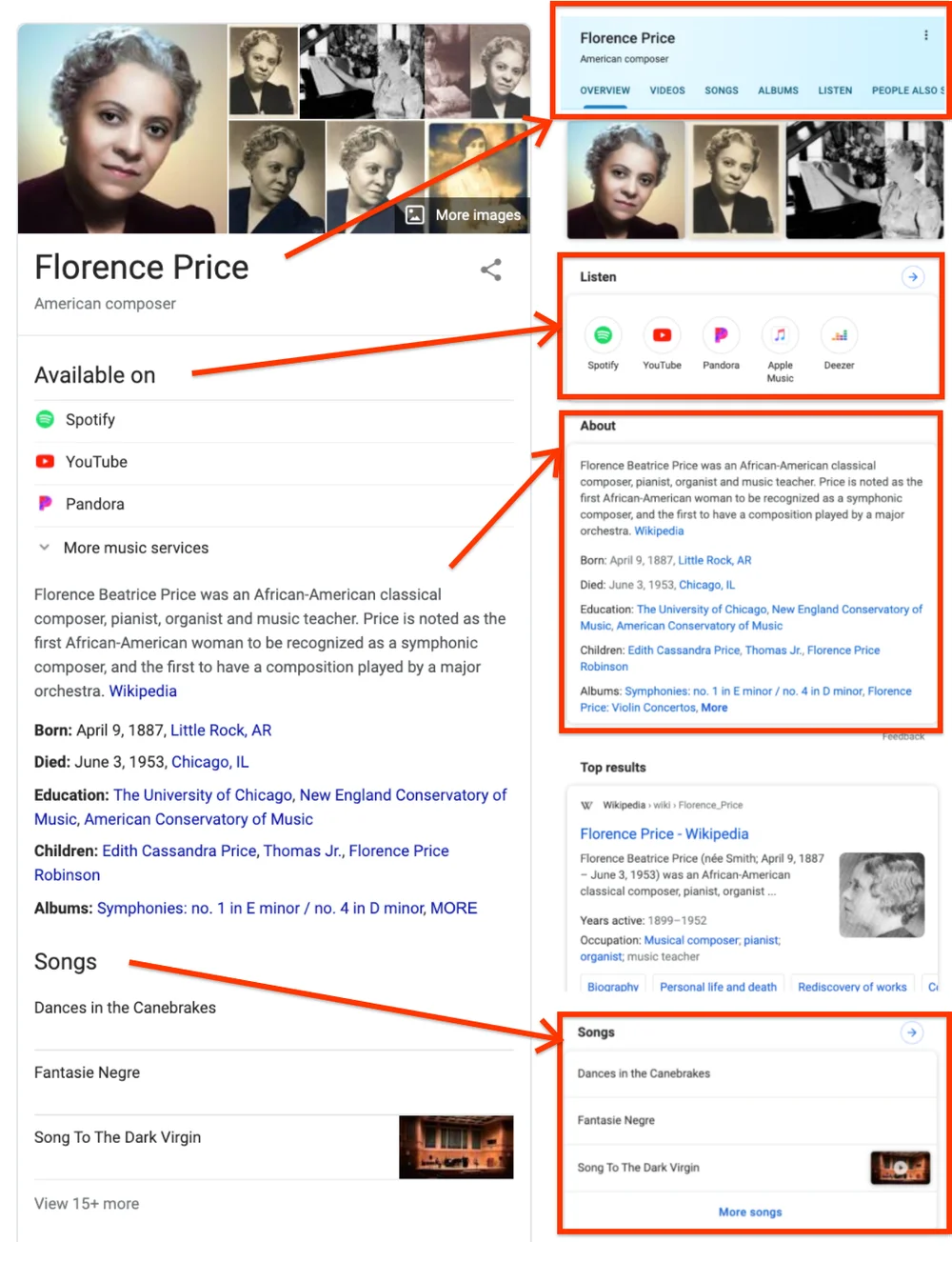
Each entity is stored in a structured format. It includes:
- A name.
- An Entity ID, which distinguishes objects that share the same name.
- Categories, such as company, organisation or technology firm.
- Attributes — dates, numbers or descriptive details.
- For a person: date of birth, occupation, notable achievements.
- For a book: publication year, author, publisher.
Another important element is relationships — the links between entities: ownership, location, affiliation. Together, these relationships form the knowledge graph, a network of nodes and connections that models the world as Google understands it.
How entities influence ranking algorithms
After identifying the entities and the relationships in the content, the search engine uses this information to evaluate relevance and rank the page. Google does not fully disclose how entity signals are applied, but patents and industry experiments point to several important factors.
| Factor | What algorithms assess | Why it matters for ranking | Example |
|---|---|---|---|
| Entity co-occurrence | How often two entities appear together in authoritative sources | A page about one entity is likely to be relevant to the other connected entity, even if it is mentioned infrequently | Paris and the Eiffel Tower |
| Entity authority | The overall weight of an entity based on links, mentions and citations | A niche entity can be dominated by a well-optimised site; broader entities require more signals such as backlinks, mentions and fresh content | Electric cars (competitive) vs. restomod cars (niche) |
| Entity salience | How important a specific entity is for explaining the topic of a page | Highlighting achievements or meaningful attributes strengthens the connection between the entity and the subject | A scientist whose profile notes their Nobel Prize |
| Intent disambiguation | The system’s ability to determine which entity the user meant when a query is ambiguous | Pages are ranked by meaning rather than literal phrasing | “Fresh apple” (fruit) vs. “Apple stock price” (company) |
Entities do not replace the classic foundations of SEO. Keywords still matter because they set the topic. Entities help reveal the connections between these topics and clarify the context. Backlinks remain essential, but it is not only the link itself that matters; the relevance of the linking site matters as well. The closer the donor site is to your subject area, the more weight the link carries, and entities help search engines evaluate that closeness.
For SEO specialists, this means that sites understood by search engines at the entity level gain an advantage. Their content appears meaningful, structured and authoritative to the algorithms, which influences how they rank.
The role of structured data in entity-based SEO
Structured data helps search engines interpret a page correctly because well-written text is not enough. The code also has to communicate the meaning clearly. Schema.org markup in JSON-LD format allows you to specify the entities on a page and the details associated with them.
Structured data acts as a language that tells the search engine: “this is the name of the organisation”, “this is the address”, “this is the product and its attributes”, “this is the rating and the reviews”.
First, Schema.org markup lets you define the type of an entity. For example, an article about a well-known person can use the Person type to signal that the subject is an individual, with fields such as birthDate for their date of birth.
If you run a corporate blog, you can mark the company name as Organization and add sameAs links to official profiles such as Wikipedia or social media. This connects your organisation to a recognised entity in the knowledge base and makes identification easier for the algorithm.
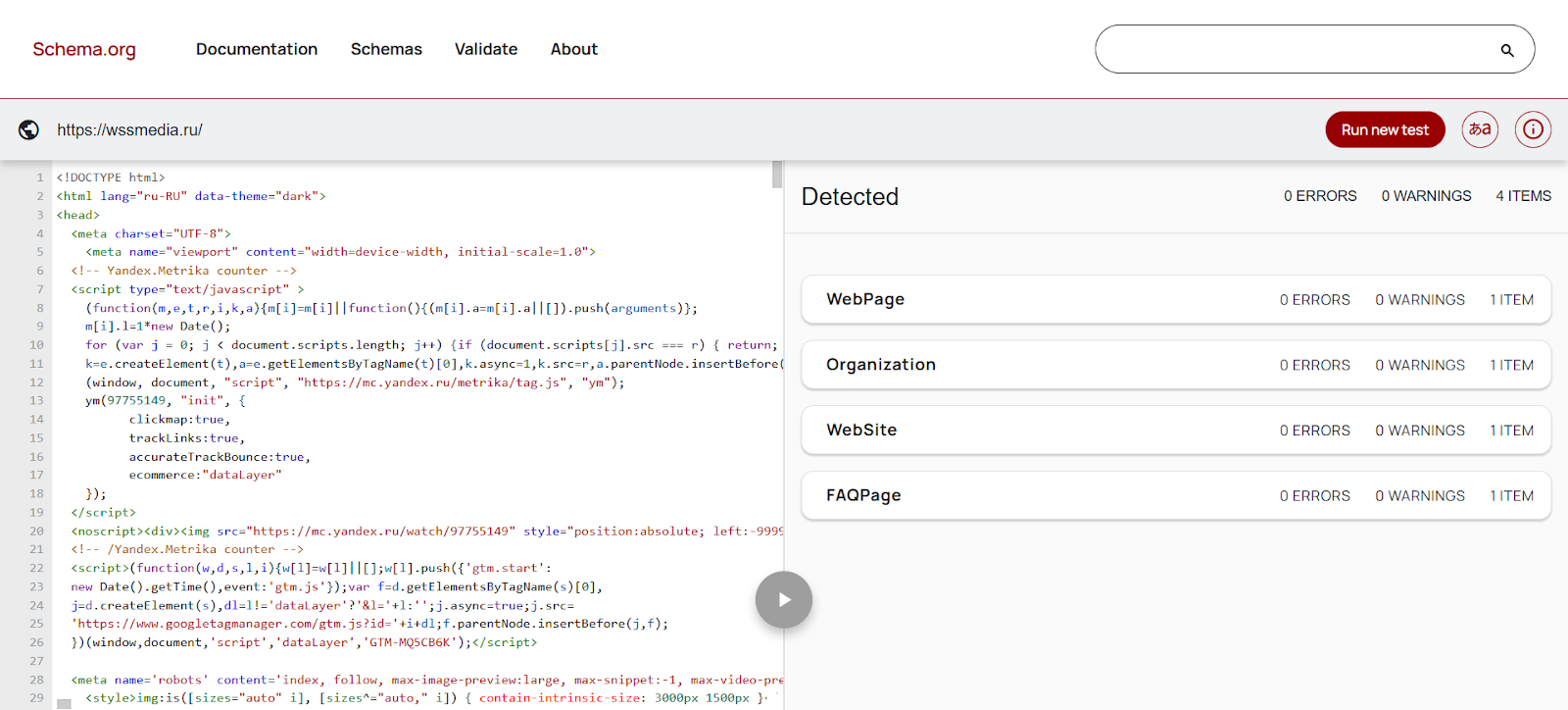
Second, structured data is often required for a page to appear in rich results. A Knowledge Panel for a brand or a person, rich snippets with recipes, ratings or FAQ sections — many of these elements are generated from the markup.
In practice, well-defined entities in Schema.org markup help the search engine understand the page and decide which additional information can be shown to the user. For example, if an event page is marked up with the Event type (date, location and other details), it may appear in the events block in search. The FAQ type can add a list of questions and answers under the search snippet. These elements improve visibility, increase CTR and indirectly help grow organic traffic.
Structured data also formalises the relationships between entities on the page. On a product page, you can specify that a product (Product) is made by a certain organisation (Organization) and that it has reviews (Review) from identifiable people (Person). This creates a small knowledge graph in the code, which helps the algorithm interpret the content more accurately.
→ Implementing Schema.org markup does not improve rankings on its own, but it works as a catalyst. A search engine tries to satisfy the user’s request as accurately as possible, so all else being equal, it will prefer a page where it is clear who is who.
The main thing is to avoid mistakes in the markup. Typical issues include duplicating the same Schema across all pages and using types that do not match the content. The data must reflect what is actually on the page. You cannot mark elements that do not exist or use the Schema in ways that go against the guidelines. This can lead to penalties, such as Google’s actions for “misleading markup”.
But when the markup is implemented correctly, the benefit is clear: you give the search engine a blueprint of the entities and their properties, making semantic interpretation easier.
Clarity in the code means clarity in search
Our team aligns Schema with the entities on the page, highlights what matters, and removes the inconsistencies that create ambiguity for algorithms.
An entity-driven content strategy
Transitioning to Entity SEO requires rethinking how content is planned and structured. Instead of chasing individual high-volume keywords, the focus shifts to topic coverage and the meaningful connections between materials.
Let’s look at the core principles of this approach.
Identify the key entities in your topic
During the research stage, map out which objects are connected to your niche: people, companies, products, technologies and concepts. For a cooking website, these would include dishes, ingredients, chefs and world cuisines. Instead of collecting thousands of keywords without a clear logic, you get a “map” of entities — an understanding of what is actually important to cover.
Build content hubs around entities
An effective approach is to create content clusters on your site. One page covers the topic as a whole, and supporting pages expand on the subtopics. These pages are connected through internal links and together explain an entity or a group of related entities.
For example, an article titled “What is blockchain” (the entity blockchain) links to materials such as “Blockchain use cases in finance”, “History of the technology” and “Pros and cons”. All of these pages link to each other and form a clear cluster for the search engine. This demonstrates expertise and comprehensive topic coverage, which has a positive impact on rankings.

Consider user intent
When planning content, think about the different types of queries users make in your niche. Alongside informational articles, it is helpful to create FAQ sections, glossaries of terms and “how-to” guides. Question-based searches such as “how to set up…” or “what is the difference between…” are often directly tied to entities. If you include answers to these questions in your materials, you can capture more of the relevant search demand.
Use variations and synonyms
One entity can appear under different names. A city, for instance, may have a full name, abbreviations or local short forms. You can include these alternatives when they are relevant. For example: Los Angeles (also known as LA). This helps the content stay relevant to different queries that point to the same entity. The key is to use these variations naturally and avoid turning the text into a list of synonyms.
Keep your content updated and expanding
Entities can evolve: new facts, events and details appear over time. This makes it important to revisit and update the materials on your site, adding new information when needed. Regular updates show search engines that the resource is maintained and that freshness is a priority. They also strengthen your topical authority.
Conclusion
Entity SEO is not a temporary trend but a natural stage in the evolution of search. The shift from keywords to entities has introduced a new ranking model where sites win by offering complete, well-connected and trustworthy information.
An entity-driven strategy means thinking in terms of knowledge, not isolated queries. A content strategy becomes a knowledge strategy: you aim to become a comprehensive and structured source on the entities relevant to your field. A site built this way is more resilient to algorithm changes because it speaks the search engine’s language, the language of entities and their relationships.


